Crash Course in Information and Absolute Entropy¶
The goal of these notes is to give a minimal introduction to the notions of information and (absolute) entropy.
Although these notes have an expository tone, the definition admonitions provide precise definitions.
Information¶
Gibbs and Shannon taught us that the likelihood of an event (according to a hypothesis) is encapsulated in the amount of useful information (according to a hypothesis) present it’s observation. Heuristically, “the information in an event scales with the amount of surprise upon it’s observation.”
Let’s imagine you’re computing information in bits, and \(\rho\) was the uniform distribution on binary sequences of length \(n\).
In this case, the information contained in a binary single string \(S\) coincides with it’s length. This happens to the be:
For example, “010” contains 3 bits of information
Definition
Given a fixed probability distribution, with density \(\rho\), with sample space \(\mathscr{X}\). For any \(x \in \mathscr{X}\), the information in x is:
Warning
We will be abusive with which base we take our logarithm with respect to. The choice of a base can be thought of choice of units, and can be recovered by examining the information of obtaining a heads in a fair coin toss.
Note
One should always remember that the notion of information depends explicitly on the probability distribution. Information is very “context-dependent.”
Below is a plot of information of an event as a function of it’s likelihood:
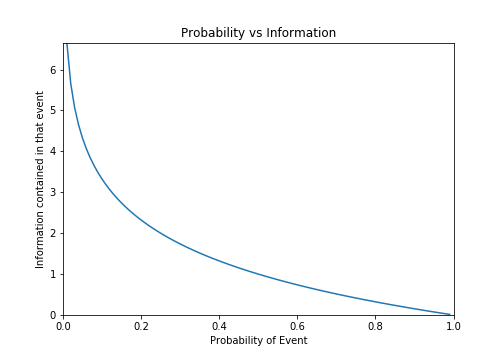
Note
While an event with probability 1 has no information, an event with probability 0 has an infinite amount of information.
If obtaining information IRL requires the expenditure of energy, this provides an articulation of an event being “impossible” in the same sense it is “impossible” to go faster than the speed of light.
Heuristically, information is dual to likelihood/probability:
- High likelihoood events have litle (useful!) information.
Knowing it’s not going to rain next saturday has little useful information if you live in a desert.
\(2 + 2 = 4\) (which we’re certain is true) has zero information.
- Low likelihood events have a lot of (useful!) information.
Knowing it’s going to be sunny next saturday has a lot of useful information if you live in Seattle.
\(2 + 2 \neq 4\) has an infinite amount of information.
Entropy¶
Information is a pairing between events and probability distributions. More formally, it’s a function:
In other words, it gives a random variable for each probability distribution \(\rho\):
whose expectation value provides a numerical invariant of \(\rho\), namely it’s entropy.
We briefly pause to introduce some
Notation
Given a random variable \(X\) and a probability distribution \(\rho\), we let
denote the expectation value of \(X\) with respect to the distribution \(\rho\)
We can now state the
Definition of Entropy¶
Definition
The (absolute) entropy of \(\rho\) is just the expected amount of information \(\rho\) contains:
Below is the a graph of a the entropy of biased coin toss as function of the probability of heads:
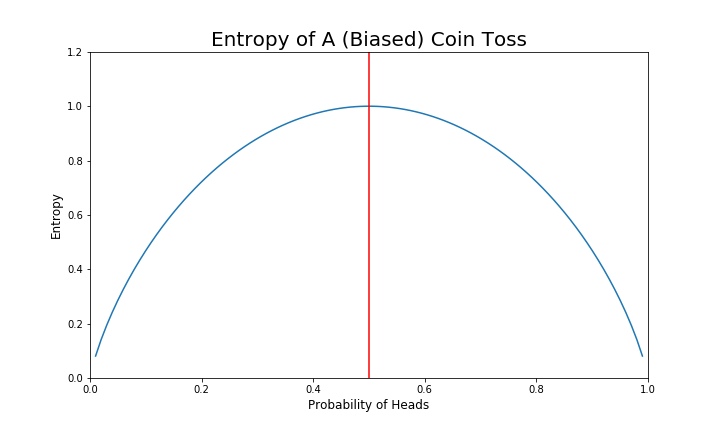
Note
Entropy is maximized when the coin is fair!
Entropy is minimized when the coin has no randomness!
This is the first indication that we can think of entropy as quantifying the amount of uncertainty in a system.
Note
An essential feature of this definitions is that \(x\) goes to 0 much faster than \(\log(x)\). In other words,
This ensures that impossible events do not cause the entropy to be infinite.
Entropy of a Normal Distribution¶
The amount of information in a univariate normal distribution \(\mathcal{N}(\mu, \sigma)\), is easy to compute:
This gives a gorgeous description of it’s entropy:
Note
We see further evidence for the heuristic that entropy quantifies the randomness of the distribution, as it increase monotonically with the standard deviation.
Note
In general, entropy is translation/permutation invariant. Fortunately, it is not dialation invariant.
The formula for a multivariate Gaussian is analagous but more complex. What’s most interesting is a manifestation of the curse of dimensionality:
So that the entropy of a unit normal scales linearly with the dimension.
Note
A general fact is that normal distributions maximize the entropy amongst all distributions with a fixed mean and variance.
More generally, all exponential families (e.g. Boltzman distributions, exponential, multinomial, …) arise by a similar “Maximum Entropy Principle.”